Functional Programming
While most concepts explained in this section are general, the
syntax and the examples will be given in Java. Things in Python are
rather similar and you can
read the details here (click on the Python stub.)
One of the core ideas of functional programming is that
functions can be arguments to other functions. For instance, a
function implementing a sorting algorithm may take as a parameter the
comparison function along with the data to be sorted.
Java 8 introduced support for this style of programming by adding
new syntax for specifying so-called anonymous functions, also
called lambdas. This syntax allows to write functions
directly in the argument list of other functions. The syntax for
specifying a function is the following:
(T1 param1, T2, param2, ...) -> {
// Body of the function with as many statements as you need
// separated by semicolons, just like regular Java statements.
return /* possibly something */;
}
where T1 and T2 are the types of param1 and param2, respectively.
If the function is made by a single statement, a more concise syntax can be used:
(T1 param1, T2 param2) -> /* single statement with no semicolon */
the result of the single statement will be the return value of the function.
If the type of the parameters can be inferred from the context, it can be omitted.
An example will make things clearer.
Imagine you have a collection coll of Double with a method map (more on such collections later).
The map method transforms the collection into a new one by applying the function passed as a parameter to each element.
Therefore, to obtain a collection of the squared values you should do the following:
coll.map((Double x) -> x*x);
Since the collection is of Double, the compiler can infer the type of x, so in this case we can write:
To make another example, imagine that you want to transform your collection of Double into a collection of differences from some other value, defined in a variable:
double fixed = 1.5;
coll.map((x) -> {
double diff = fixed - x;
return diff;
});
Note that fixed is used in the body of the anonymous function, but is defined outside of it!
In such cases we say that the anonymous function captures a variable.
You cannot re-assign a captured variable within an anonymous function.
Trying to do it will result in a compilation error mentioning that all captured variables must be effectively final, which is the compiler’s way of saying that you cannot re-assign them.
Java 8 also introduced another way of passing functions to other functions, namely method references.
Suppose you have the following class:
public class Operations {
public static double square(double x) {
return x * x;
}
}
You may pass the static method square to the method map instead of defining a lambda function, like in the examples above.
The syntax to refer the static method square is the following:
coll.map(Operations::square);
note the double colon joining the method name square to the class it belongs to, Operations.
Therefore, you have two ways of passing a function to a method: either you pass an anonymous function or a method reference.
Usually, lambda functions are used when the functionality can be coded in a few statements and is limited to a single occurrence.
Method references, on the other hand, are useful when the code gets more complex or when it should be reused in several places.
Mini-guide to Spark implementation of MapReduce algorithms
Below we give a brief description of the most relevant Spark features
and methods which can be used for the implementation of MapReduce algorithms.
The presentation refers to Java as a default, reporting
main differences with Python, when needed. For minor
differences with Python (e.g., in the syntax), refer to the official
Spark Python API.
Configuration
First, let us look at the basic settings required in your program to
use Spark, which were already present in the template provided for Homework 1.
The entry point to Spark is the Spark context. Since Spark can
run on your laptop as well as on many different cluster architectures,
to simplify the user experience Spark developers have created a single
entry point that handles all the gory details behind the scenes.
To create the context you first need to provide some configuration
using
SparkConf configuration =
new SparkConf(true)
.setAppName("application name here")
Let’s break down the code snippet above. We pass true to the SparkConf
constructor. This has the effect that configuration
properties can also be passed on the command line. Alternatively,
they must be set invoking suitable methods
from the SparkConf object being created. For example,
the code above sets the name of the application in this fashion.
There is a configuration property, the master,
which is important to ensure the correct execution of a program.
This can be set by invoking method
.setMaster(master-address) after the .setAppName method
from the SparkConf object being created (although for this course
you do not need to use this method as explained below).
As detailed in the Spark
documentation, there
are several values that the master address can take. For example:
"local[*]": uses the local resources of the computer. This sets up a Spark process on the local machine, using the available cores for parallelism.
This master address must be used when testing code on your local machine.
However, Python users do not need to explicitly set this master, since it is the default, while for Java users it is convenient
to set the master using the VM options in the Intellij interface, rather than using the aforementioned setMaster method.
This choice gives the flexibility of running the code on different
architectures.
"yarn": runs Spark on the Yarn cluster manager. This is the cluster manager used by the cluster
available for the course. However, take notice that
when you run the code on the cluster through
the spark-submit command that we instruct you to use, the master is
automatically set to yarn, so you do not need to explicitly do the setting.
Just make sure, in this case, that you are not accidentally
setting it to local[*].
Based on the cofinguration object conf
created above,
the Spark context is instantiated as follows:
JavaSparkContext sc = new JavaSparkContext(conf).
Reading from a file
A way (but not the only one!) to read an input dataset
is to store the dataset as a text file,
located at some path filepath
which is passed as input to the program,
and then load the file into an RDD of strings,
with each string corresponding to a distinct line in the file:
JavaRDD<String> lines = sc.textFile("filepath").
The filepath can be substituted with args[0], if it is
passed as the first parameter on the command line.
Note that if a path to a directory
rather than to a file is passed to textFile, it
will load all files found in the directory into the RDD.
Key-value pairs
For Java users.
In Java, a dataset of key-value pairs with
keys of type K and values of type V
is implemented through a
JavaPairRDD<K,V> object, which is
an RDD whose elements are instances of the class
Tuple2<K,V> (from the Scala standard library). Given a
pair T, instance of Tuple2<K,V>, the methods
T._1() and T._2() return the key and the value
of the pair, respectively.
For Python users. In Python, a dataset
of key-value pairs can be implemented as a simple RDD whose elements
are built-in Python tuples.
More on RDDs of key-value pairs in Spark (both for Java and Python users) can be found
here.
Map phase In order to implement a map phase
where each key-value pair, individually, is transformed into
0, 1 or more key-value pairs, the following methods
can be invoked from an instance X of JavaPairRDD<K,V>:
-
mapToPair(f).
(The method can also be invoked from a JavaRDD<T> object.)
It applies function f passed
as a parameter to each individual key-value pair of X, transforming it into
a key-value pair of type Tuple2<K',V'>
(with arbitrary K' and V'). The result is a
JavaPairRDD<K',V'>. Note that the method cannot be
used to eliminate elements of X, and the returned RDD has the same number
of elements as X. To filter out some elements from X, one can invoke
either the filter or the flatMapToPair methods
described below.
-
flatMapToPair(f). It applies function f passed
as a parameter to each individual key-value pair of X, transforming it into
0, 1 or more key-value pairs of type Tuple2<K',V'>
(with arbitrary K' and V'), which are returned as an iterator.
The result is a JavaPairRDD<K',V'>.
(The method can also be invoked from a JavaRDD<T> object.)
-
mapValues(f). It transforms
each key-value pair (k,v) in X into
a key-value pair (k,v'=f(v)) of type
Tuple2<K,V'> (with arbitrary V')
where f is the function passed as a parameter.
The result
is a
JavaPairRDD<K,V'>.
-
flatMapValues(f). It transforms each key-value pair
(k,v) in X into multiple key-value pairs (k,w_1), (k,w_2) , ... of
type Tuple2<K,V'> (with arbitrary V').
The w_i's are returned as an Iterable<V'>
by f(v), where f is the function passed as a parameter.
The result is a
JavaPairRDD<K,V'>.
Reduce phase
In order to implement a reduce phase
where each set of key-value pairs with the same key are transformed into
a set of 0, 1 or more key-value pairs, the following methods
can be invoked from a JavaPairRDD<K,V> object X:
-
groupByKey().
For each key k occurring in X,
it creates a key-value pair (k,w)
where w is an Iterable<V>
containing all values of the key-value pairs with key k
in X.
The result is a
JavaPairRDD<K,Iterable<V>>.
The reduce phase of MapReduce can be implemented by
applying
flatMapToPair after groupByKey.
-
groupBy(f). It applies function f passed as a
parameter to assign a key to each element of X. Then, for each
assigned key k creates a key-value pair (k,w) where w is
an Iterable<K,V> containing all elements of X that
have been assigned key k. The result is a
JavaPairRDD<H,Iterable<K,V>>, where H is the
domain of the keys assigned by f. The partitions induced by f can
then be processed individually by applying a method such
a flatMap or flatMapToPair to the RDD
resulting from
groupBy.
-
reduceByKey(f).
For each key k occurring in X, it creates a key-value pair (k,v) where
v is obtained by aggregating all values of the key-value pairs with key
k through the function f passed as a parameter. For example, if f is specified
as (x,y)->x+y, then v will be the sum of all values of the key-value pairs with key k. The aggregation is performed efficiently exploiting the partitions of the RDD X created by Spark (perhaps as a consequence of the invocation of
the repartition method): first the values are aggregated within each partition,
and then across partitions. The result is a
JavaPairRDD<K,V>.
For Python users. All of the above
methods have a Python equivalent with the same name, except
for mapToPair and flatMapToPair which, in
Python, become map and flatMap. Some
transformations, however, require that the elements of the RDD be
key-value pairs.
Partitioning
An RDD is subdivided into a configurable number of partitions,
which may be distributed across many machines. For transformations
acting on individual elements of an RDD (e.g., those listed above to
implement the Map phase of a MapReduce round), Spark defines a number
of tasks equal to the number of partitions. Each task
corresponds to the application of the given transformation to the
elements of a distinct partition. Also, in Spark each machine is
called an executor, and may have many cores. Each task
will be assigned to a core for execution. A higher number of
partitions allows for better exploitation of the available cores,
better load balancing and smaller local space usage. However, managing
too many partitions may eventually introduce a large overhead.
The number of partitions, say num-part, can be set by
invoking the
repartition(num-part) method.
In this case, the elements of the RDD are randomly shuffled among the partitions
and this is a way to attain a random partitioning.
Important: since RDDs are immutable,
the number of partitions can be set only when the RDD is first defined.
Let X,Y,Z be RDD variables and
consider the following sequence of 3 instructions:
Y = X.repartition(4)
Y.repartition(8)
Z = Y.repartition(8)
After the 3 instructions have been executed, Y is subdivided into 4
partitions (the second instruction has no effect on its partitioning)
and Z is subdivided into 8 partitions.
The number of partitions can also be passed as input to the
textFile method described above
(e.g.,
JavaRDD<String> docs = sc.textFile("filepath",num-part),
but in this latter case it is regarded as a "minimum" number of
partitions and also the achieved patition is not necessarily random.
Let X be an RDD containing objects of type T, partitioned into p partitions.
The following methods allow you to gather
and work separately on each partition.
-
mapPartitions(f)
and mapPartitionsToPair(f). They apply function f passed as a parameter
to the elements of each partition, which are assumed to
be provided as an
iterator. Function f must return
0, 1 or more objects of some type T'. Hence, the result is a
JavaRDD of elements of type T'.
If mapPartitionsToPair
is used, then type T' must be
Tuple2<K',V'> and the result is a
JavaPairRDD<K',V'>.
glom() (the name says it all :-).
It returns an RDD whose elements are arrays (Java) or lists (Python)
of objects of type T, and each such array/list
contains the objects of a distinct partition
of X. The partitions can then be processed
individually by applying a method such a flatMap
or flatMapToPair, with a suitable to the RDD resulting from glom.
For Python users. All of the above
methods have a Python equivalent with the same name, except
for mapPartitionsToPair which does not exist in the Python API.
Additional useful methods
The following methods can be invoked from an RDD X of elements of type T.
count(). An action that returns the number of elements in X.
map(f). A transformation that applies function f to each individual element X.
Function f accepts a single input of type T and returns an output of type R.
The following example shows how to transform a RDD of integers into a RDD of doubles
by halving each element of the original collection:
JavaRDD<Integer> numbers;
JavaRDD<Double> halves = numbers.map((x) -> x / 2.0);
reduce(f). An action that returns
a single value of type T by combining all the values of the RDD according to function f, which
must be associative and commutative, since there is no guarantee on the order of application to the elements of the RDD.
For example, to get the sum of all the elements of a RDD of integers:
JavaRDD<Integer> numbers;
int sum = numbers.reduce((x, y) -> x + y);
this method should not be confused with the Reduce Phase in MapReduce. They
are rather different things!
filter(f) A transformation that returns an RDD containing only the elements
in X for which f returns true. Function f accepts a single input of type T and returns a boolean.
The following example shows how to obtain a RDD of even numbers from an RDD of integers:
JavaRDD<Integer> numbers;
JavaRDD<Double> evenNumbers = numbers.filter((x) -> x % 2 == 0);
countByValue(). An action that returns a
Map/Dictionary that for each element e in the RDD X contains an entry
(e,count(e)), where count(e) is the number of occurrences of e in
X. For example, suppose that X contains integers, to save the number
of occurrences of each distinct integer into a Map/Dictionary countMap, in Java you write Map<Integer,Long> countMap = X.countByValue() while in Python you write countMap = X.countByValue();
sortByKey(ascending). A transformation that can be applied when the
elements of X are key-value pairs (in Java X must be an JavaPairRDD). Given a boolean parameter
ascending, it sorts the elements of X by key in increasing order (ascending = true) or in
decreasing order (ascending = false). The parameter ascending is optional and, if missing, the
default is true. Calling collect() on the resulting RDD will output an ordered
list of key-value pairs (see example after collect()).
collect(). An action that
brings all the data contained in X (which may be distributed across multiple executors)
into a list stored on the driver. Warning: this action needs enough memory
on the driver to
store all data in X, hence it must be used on when the RDD is sufficiently small, therwise
an OutOfMemoryError will be thrown and the program will crash.
For example:
JavaRDD<String> distributedWords;
List<String> localWords = distributedWords.collect();
// localWords is a local copy of all the elements of the distributedWords RDD.
The following further example in Java shows how to print all elements of a
JavaPairRDD<Long,String> X, sorted by the key (of type Long):
for(Tuple2<Long,String> tuple:X.sortByKey().collect()) {
System.out.println("("+tuple._1()+","+tuple._2()+")");
}
take(num). An action that brings the first num elements of X
into a list stored on the driver. When elements of X are key-value pairs, calling
take(num) after sortByKey return the first num pairs in the
ordering.
min(comp), max(comp). These are actions that return the minimum/maximum element in X,
respectively. The usages in Java and Python are slightly different, and they are
explaoned below.
Java users. The argument comp is an object of a class implementing
the java.util.Comparator interface. The interface defines a
method compare which must adhere to the following
contract. Two arguments of the same type are given. If they are
equals, the method should return 0, if the first is smaller a negative
number should be returned, if the first is greater then a positive
number should be returned. However, there is an issue in Spark’s Java
API. Spark needs functions to be serializable, because it has to send
them to executors, but java.util.Comparator is not seralizable, so
anonymous functions passed to max or min are not serializable, even if
they could be. This is a limitation of the Java compiler. Therefore,
passing an anonymous function to max or min will cause your code to
crash at runtime with a TaskNotSerializableException.
Fortunately, there is a workaround: you can explicitly define a static class
implenting both Comparator and Serializable. Here is an example
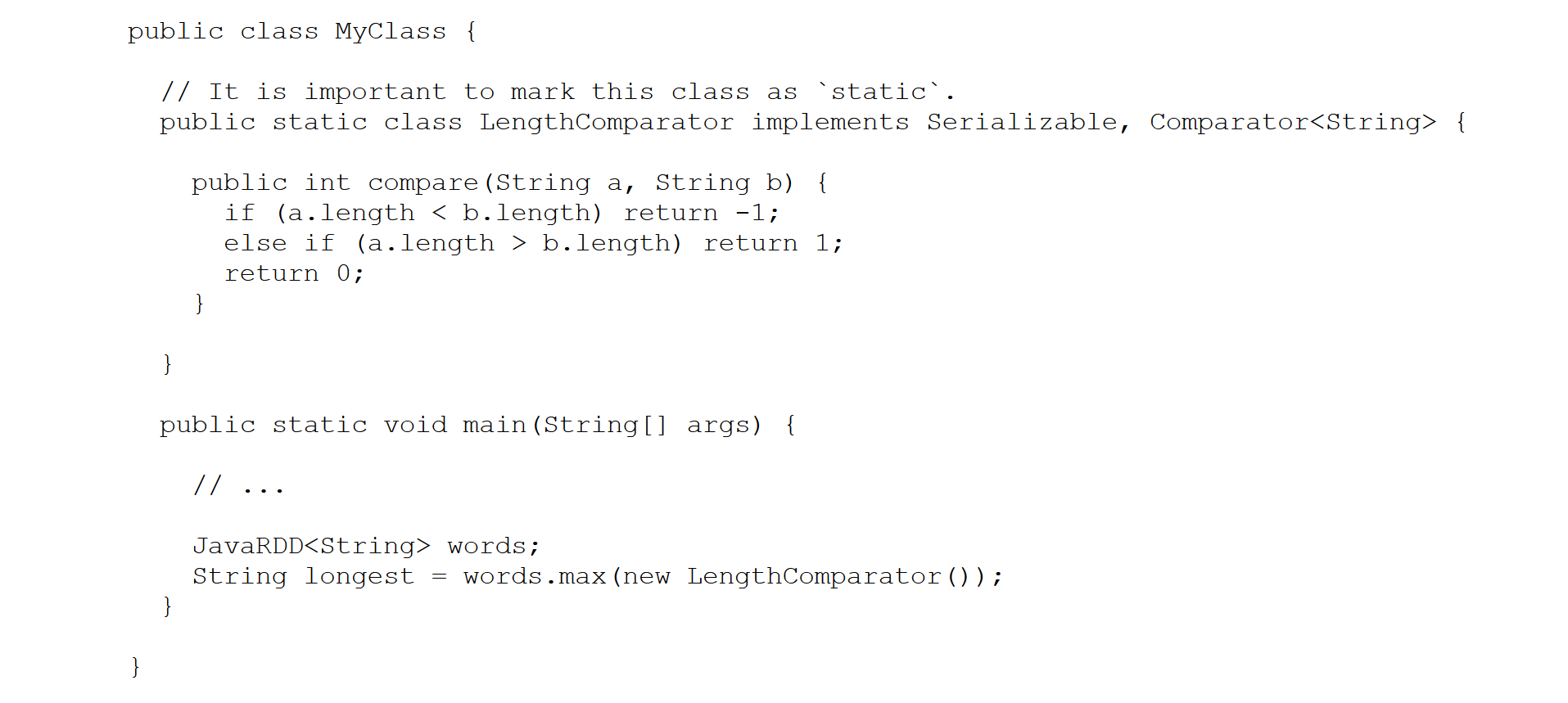
Python users. The argument comp is optional. If given,
it is a function which, applied to each element of the RDD,
returns the key used to determine the min/max.
Shared variables
Sometimes, read-only global data must be used by RDD trasformations (e.g.,
by the functions applied through methods such as map, flatMap or flatMapToPair). Let Var be a variable of type T defined in the main program and to be used in read-only fashion.
RDD trasformations can simpy use Var in their code, as a
global variable, but it is required that Var be assigned
only once. Spark will create a copy of the variable for
each task that needs the variable, and will ship the copy to the worker executing
the task.
If the variable is a structure contaning several elements (e.g., an array or list), the above approach can be time and space consuming. In this case, it is more efficient to encapsulate Var as
broadcast variable, say sharedVar, by invoking
Broadcast<T> sharedVar = sc.broadcast(Var) (in Java)
sharedVar = sc.broadcast(Var) (in Python)
In this case, only one copy of the variable will be created in the
memory of each worker and Spark will only ship a reference to the
variable to the tasks that use it. The value of this broadcast
variable can be accessed by invoking sharedVar.value()
(in Java) and sharedVar.value (in Python). Here is a Java
example
int[] myArray = {7, 9, 12};
Broadcast<int[]> sharedArray = sc.broadcast(myArray);
int i = sharedArray.value()[1]; // i=9
The same example in Python:
myList= [7, 9, 12]
sharedList = sc.broadcast(myList)
i = sharedList.value[1] # i=9
There are also special shared
variables, called
accumulators, which can be modified but only through associative and commutative operators such as additions. For more details, see what the offical Spark documentation saysabout
shared variables.
Profiling
Time measurements
In Java, measuring time can be done thorugh
the System.currentTimeMillis() method. In Spark,
however, the use of this method requires some care due to the fact
that transformations are lazy, in the sense that they are
executed only once an action (such as counting the elements or writing
them to a file) requires the transformed data. If you do the
following:
JavaRDD<String> docs = sc.textFile("filepath");
long start = System.currentTimeMillis();
// Code of which we want to measure the running time
long end = System.currentTimeMillis();
System.out.println("Elapsed time " + (end - start) + " ms");
then you would be measuring also the time to load the text file!
Indeed, sc.textFile is not executed
immediately, rather it is executed when an action requires
it, after the start of the stopwatch. Therefore, if you want
to exclude the time to load the text file from your measurements, you
need to force the loading to happen before the stopwatch is
started. In order to do so, you can run an action on the
docs RDD, and the simplest one is count().
However, simply invoking count would not do: we have to explicitly tell Spark to cache the results in memory. In the above example, the
first line should become as follows:
JavaRDD<String> docs = sc.textFile("filepath").cache();
numdocs = docs.count();
There are several alternatives for caching an RDD in memory.
They are described
here.
Web interface
You can monitor the execution of Spark programs through a web interface.
- In local mode:
The interface runs alongside your program, and
exits when the program terminates. In order to have time to consult
it, you must suspend the execution of the program. The simplest way
is by inserting an input statement right before the end of
your
main method. For instance, in Java you could insert
these two instructions at the end of the method (you can do a similar thing in Python):
System.out.println("Press enter to finish");
System.in.read();
Now, when your program reaches the input statement, open a browser and
visit localhost:4040. You will see the web
interface of your running program
-
On the cluster
To invoke the web interface to monitor jobs running on CloudVeneto, from your browser go to url:
http://147.162.226.106:18080/
The access is allowed only from the unipd network.
You will see the list of all applications (even those of other groups)
already executed. (At the end of the list there is also a link to the
list of incomplete applications.) There is a line for each application
reporting enough information to allow you to indentify the application
you want to monitor. Click on the link in the first column (App ID) to
get the details of the application. You will get the same interface as
the one that you used locally on your PC.
Unfortunately, the web interfaces have no (or little) documentation.
However, you are encouraged to explore them on your own.
Official and additional documentation
Apache Spark Site
For Java users.
Refer to the official
RDD Programming guide, to the
JavaRDD and JavaPairRDD classes in the
Spark Java API.
For Python users.
Refer to the official
RDD Programming guide and to the RDD class in the
Spark Python API.
|