|
|
16 |
|
|
|
|
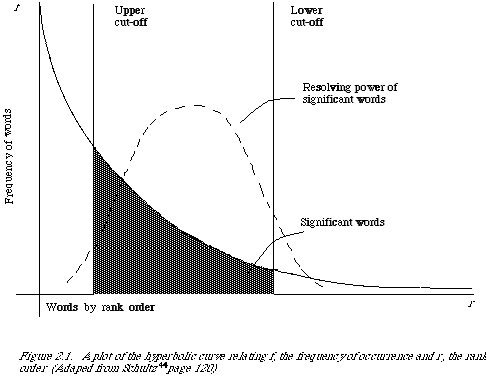
upper and a lower (see Figure 2.1.), thus excluding non-significant words.
The words exceeding the upper cut-off were considered to be common and those below the lower cut-off rare, and therefore not contributing significantly to the content of the article.
He thus devised a counting technique for finding significant words.
Consistent with this he assumed that the resolving power of significant words, by which he meant the ability of words to discriminate content, reached a peak at a rank order position half way between the two cut-offs and from the peak fell off in either direction reducing to almost zero at the cut-off points.
A certain arbitrariness is involved in determining the cut-offs.
There is no oracle which gives their values.
They have to be established by trial and error.
It is interesting that these ideas are really basic to much of the later work in IR. Luhn himself used them to devise a method of automatic abstracting. He went on to develop a numerical measure of significance for sentences based on the number of significant and non-significant words in each portion of the sentence. Sentences were ranked according to their numerical score and the highest ranking were included in the abstract (extract really). Edmundson and Wyllys[8] have gone on to generalise some of Luhn's work by normalising his measurements with respect to the frequency of occurrence of words in general text.
There is no reason why such an analysis should be restricted to just words. It could equally well be applied to stems of words (or phrases) and in fact this has often been done.
|
|
|
16 |
|
|
|