|
|
29 |
|
|
|
|
subsets differing in the extent to which they are about a word w then the distribution of w can be described by a mixture of two Poisson distributions.
Specifically, with the same notation as before we have
here p1 is the probability of a random document belonging to one of the subsets and x1 and x2 are the mean occurrences in the two classes. This expression shows why the model is sometimes called the 2-Poisson model. It is important to note that it describes the statistical behaviour of a content-bearing word over two classes which are 'about' that word to different extents, these classes are not necessarily the relevant and non-relevant documents although by
* Although Harter[31] uses 'function' in his wording of this assumption, I think 'measure' would have been more appropriate.
assumption (1) we can calculate the probability of relevance for any document from one of these classes. It is the ratio
that is used to make the decision whether to assign an index term w that occurs k times in a document. This ratio is in fact the probability that the particular document belongs to the class which treats w to an average extent of x1 given that it contains exactly k occurrences of w. This ratio is compared with some cost function based on the cost a user is prepared to attach to errors the system might make in retrieval. The details of its specification can be found in the cited papers.
Finally, although tests have shown that this model assigns 'sensible' index terms, it has not been tested from the point of view of its effectiveness in retrieval. Ultimately that will determine whether it is acceptable as a model for automatic indexing.
Discrimination and/or representation
There are two conflicting ways of looking at the problem of characterising documents for retrieval. One is to characterise a document through a representation of its contents, regardless of the way in which other documents may be described, this might be called representation without discrimination. The other way is to insist that in characterising a document one is discriminating it from all, or potentially all, other documents in the collection, this we might call discrimination without representation. Naturally, neither of these extreme positions is assumed in practice, although identifying the two is useful when thinking about the problem of characterisation.
|
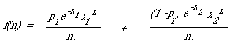
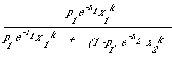
|
|
29 |
|
|
|