|
|
46 |
|
|
|
|
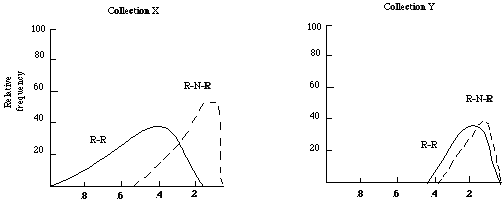
relevant-relevant (R-R) and relevant-non-relevant (R-N-R) associations of a collection.
Plotting the relative frequency against strength of association for two hypothetical collections X and Y we might get distributions as shown in Figure 3.2.
From these it is apparent: (a) that the separation for collection X is good while for Y it is poor; and (b) that the strength of the association between relevant documents is greater for X than for Y.
Figure 3.2. R-R is the distribution of relevant-relevant associations, and R-N-R is the distribution of relevant-non-relevant associations.
It is this separation between the distributions that one attempts to exploit in document clustering. It is on the basis of this separation that I would claim that document clustering can lead to more effective retrieval than say a linear search. A linear search ignores the relationship that exists between documents. If the hypothesis is satisfied for a particular collection (some promising results have been published in Jardine and van Rijsbergen[10], and van Rijsbergen and Sparck Jones[27] for three test collections), then it is clear that structuring the collection in such a way that the closely associated documents appear in one class, will not only speed up the retrieval but may also make it more effective, since a class once found will tend to contain only relevant and no non-relevant documents.
I should add that these conclusions can only be verified, finally, by experimental work on a large number of collections. One reason for this is that although it may be possible to structurea document collection so that relevant documents are brought togetherthere is no guarantee |
|
|
46 |
|
|
|