|
|
48 |
|
|
|
|
The second criterion for choice is the efficiency of the clustering process in terms of speed and storage requirements.
In some experimental work this has been the overriding consideration.
But it seems to me a little early in the day to insist on efficiency even before we know much about the behaviour of clustered files in terms of the effectiveness of retrieval (i.e. the ability to retrieve wanted and hold back unwanted documents.) In any case, many of the 'good' theoretical methods (ones which are likely to produce meaningful experimental results) can be modified to increase the efficiency of their clustering process.
Efficiency is really a property of the algorithm implementing the cluster method. It is sometimes useful to distinguish the cluster method from its algorithm, but in the context of IR this distinction becomes slightly less than useful since many cluster methods are defined by their algorithm, so no explicit mathematical formulation exists.
In the main, two distinct approaches to clustering can be identified:
(1) the clustering is based on a measure of similarity between the objects to be clustered; (2) the cluster method proceeds directly from the object descriptions.
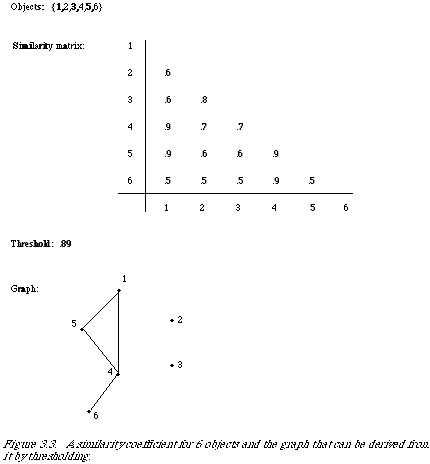
The most obvious examples of the first approach are the graph theoretic methods which define clusters in terms of a graph derived from the measure of similarity. This approach is best explained with an example (see Figure 3.3). Consider a set of objects to be clustered. We compute a numerical value for each pair of objects indicating their similarity. A graph corresponding to this set of similarity values is obtained as follows: A threshold value is decided upon, and two objects are considered linked if their similarity value is above the threshold. The cluster definition is simply made in terms of the graphical representation.
A string is a connected sequence of objects from some starting point. A connected component is a set of objects such that each object is connected to at least one other member of the set and the set is maximal with respect to this property.
A maximal complete subgraph is a subgraph such that each node is connected to every other node in the subgraph and the set is maximal with respect to this property, i.e. if one further
node were included anywhere the completeness condition would be violated. An example of each is given in Figure 3.4. These methods have been used extensively in keyword clustering by Sparck Jones and Jackson[32], Augustson and Minker[33] and Vaswani and Cameron[34].
A large class of hierarchic cluster methods is based on the initial measurement of similarity. The most important of these is single-link |
|
|
48 |
|
|
|