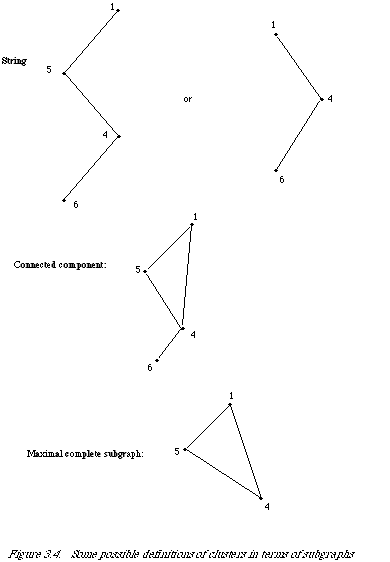
Rijsbergen[35] but, as expected, the cluster definition was so strict that very few sets could be found to satisfy it.
Efficiency has been the overriding consideration in the definition of the algorithmically defined cluster methods used in IR.
For this reason most of these methods have tended to proceed directly from object description to final classification without an intermediate calculation of a similarity measure.
Another distinguishing characteristic of these methods is that they do not seek an underlying structure in the data but attempt to impose a suitable structure on it.
This is achieved by |