Tale vincolo č necessario perché "CARICO" e "SCARICO" sono ora due entitŕ separate, e diventa quindi possibile che lo stesso valore dell'identificatore primario si ripeta in entrambe le entitŕ. In seguito alla ristrutturazione, si č anche spezzata l'associazione "Spedizione" nelle due associazioni "Spedizione" e "Ricezione", e l'associazione "Assegnazione" in "Assegnazione" e "Classifica".
Per quanto riguarda l'entitŕ "MITTENTE", si č preferito accorpare le figlie "ORGANIZZAZIONE" e "PERSONA" nel padre, aggiungendo un attributo "Tipo" che permetta di distinguere le occorrenze dell'una e dell'altra relazione. La ragione principale di questa scelta č che le entitŕ figlie partecipano ad associazioni ("Spedizione" e "Ricezione") che sono le medesime per entrambe e sono di tipo uno a molti: accorpando le figlie nel padre, quindi, nello schema relazionale sarŕ possibile collegare "CARICO" e "SCARICO" a "MITTENTE" mediante vincoli di integritŕ referenziale. Anche in questo caso, purtroppo, sono opzionali molti attributi sia del padre che delle figlie, e dunque non si puň ignorare il problema dei valori nulli; di questo, comunque, si terrŕ conto nella stesura dello schema relazionale (vedi piů avanti).
Per l'entitŕ "AFFIDATARIO", infine, si č stabilito di accorpare il padre nelle figlie, soprattutto perché queste ultime hanno molti attributi diversi. Coerentemente con questa scelta, l'associazione "Affidamento" č stata sdoppiata nelle due associazioni "Affidam_int" e "Affidam_est".
Suddivisione/accorpamento di concetti. Dopo aver studiato lo schema E-R, si č deciso che i concetti rappresentati fossero sufficientemente chiari ed omogenei, e che quindi non ci fosse bisogno di alcun accorpamento o suddivisione.
Scelta degli identificatori primari. Ogni entitŕ dello schema E-R presenta un solo identificatore, dunque non č necessario operare alcuna scelta.
Stesura dello schema. Al termine dell'analisi appena illustrata si č ottenuto il seguente schema concettuale, privo di ridondanze e di generalizzazioni:
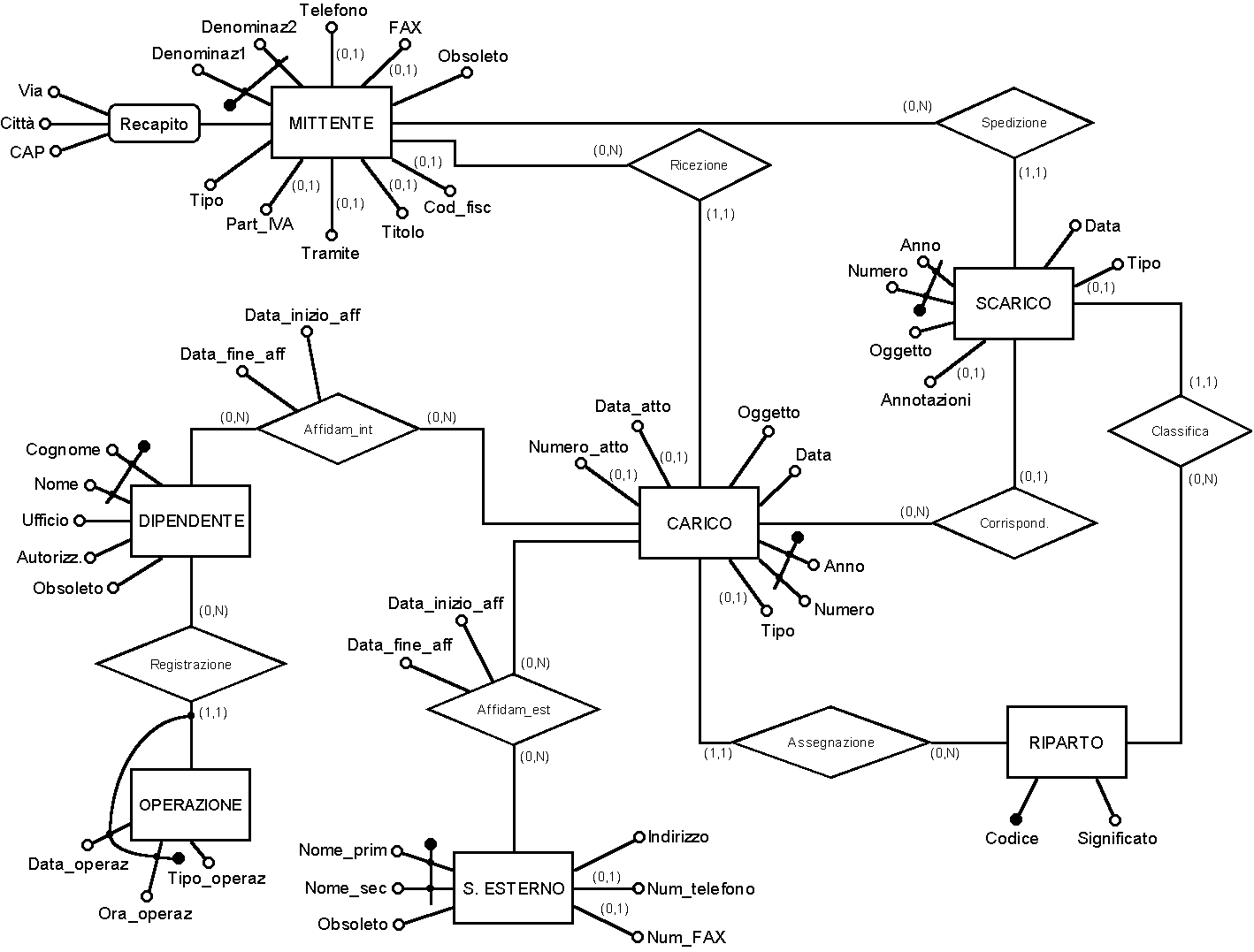
|
Come al solito, per vedere una versione ingrandita dello schema basta fare clic sull'immagine.
Dallo schema E-R allo schema relazionale
Nel passaggio dallo schema E-R allo schema relazionale, non si č dovuta risolvere alcuna particolare difficoltŕ nella traduzione delle associazioni: tutte le associazioni dello schema ristrutturato, infatti, sono binarie e di tipo semplice, cioč uno a molti (con partecipazione talvolta opzionale, talvolta obbligatoria) o molti a molti. Le associazioni del primo tipo sono state tradotte con un semplice attributo nello schema di relazione rappresentante l'entitŕ che partecipa all'associazione con cardinalitŕ 1; le associazioni del secondo tipo, invece, sono state tradotte con un intero schema di relazione.
Dato l'elevato numero di attributi opzionali presenti nello schema concettuale, lo schema relazionale č stato scritto cercando di ridurre la probabilitŕ di memorizzare tuple contenenti valori nulli; per questa ragione, le entitŕ con molti attributi opzionali sono state tradotte con:
Seguendo questa idea, l'entitŕ "SCARICO" č stata tradotta con due schemi di relazione chiamati "SCARICO" e "SCARICO_INFO_OPZ": quest'ultimo contiene l'attributo opzionale "Annotazioni". Cosě facendo, l'attributo "Annotazioni" puň essere memorizzato solo per quei documenti che effettivamente ne hanno bisogno, evitando un notevole spreco di spazio. Nell'entitŕ "SCARICO" anche l'attributo "Tipo" č opzionale, ma si č deciso di memorizzarlo per ogni documento perché, analizzando il protocollo cartaceo attualmente in uso, si č constatato che tale attributo viene utilizzato molto spesso. In base allo stesso tipo di analisi, l'entitŕ "CARICO" č stata tradotta con un unico schema di relazione.
Il lavoro di traduzione piů difficile č stato quello relativo all'entitŕ "MITTENTE". Innanzitutto, nella fase di analisi dei requisiti il gruppo si č accorto che per identificare univocamente alcune organizzazioni (come i ministeri) sono necessarie due informazioni:
Come giŕ detto, tali informazioni sono gli attributi "Denominaz1" e "Denominaz2" dello schema concettuale. Purtroppo, perň, esistono organizzazioni che non hanno alcuna divisione o sezione, e talvolta anche i ministeri sono identificati dal solo nome: nel passaggio allo schema relazionale, ciň significa che l'attributo "Denominaz2" della chiave primaria dello schema di relazione "MITTENTE" puň assumere valori nulli, e questo č inaccettabile. Per risolvere il problema, si č deciso di cambiare chiave primaria e di introdurre un nuovo attributo, chiamato "Codice": sarŕ compito del software applicativo garantire che ad ogni tupla della relazione "MITTENTE" sia univocamente assegnato un codice. La struttura effettiva del campo codice sarŕ decisa in sede di progettazione fisica.
In secondo luogo, esaminando lo schema concettuale ristrutturato ci si č resi conto che le entitŕ "MITTENTE", "DIPENDENTE" e "SOGGETTO ESTERNO" hanno molti attributi in comune: per ragioni di efficienza, si č allora scelto di tradurre queste entitŕ con un unico schema di relazione chiamato "CORRISPONDENTE_AFFIDATARIO". In altre parole, una tupla di "CORRISPONDENTE_AFFIDATARIO" puň rappresentare:
Il compito di distinguere tra queste situazioni č affidato all'attributo "Tipo". Si noti che in questo modo diventa possibile memorizzare informazioni inizialmente non previste (ad esempio, l'indirizzo di un dipendente della biblioteca): questo, comunque, non crea incongruenze, perché gli attributi di "CORRISPONDENTE_AFFIDATARIO" sono stati scelti in modo da avere pieno significato per tutti e quattro i tipi di "oggetti" che una tupla puň rappresentare; proprio per questo gli attributi "Ufficio" e "Autorizzazione", che hanno senso solo per i dipendenti della biblioteca, sono stati tradotti con uno schema di relazione a parte.
Infine, nello schema concettuale ristrutturato l'entitŕ "MITTENTE" presenta un elevatissimo numero di attributi opzionali: alcuni di questi attributi, allora, sono stati spostati negli schemi di relazione "ausiliari" chiamati "CORRISP_ORGANIZZAZIONE" e "CORRISP_PERSONA". Si noti che, in un certo senso, "ricompaiono" cosě le entitŕ figlie "ORGANIZZAZIONE" e "PERSONA" che erano state eliminate nella ristrutturazione dello schema E-R.
Al termine del lavoro di traduzione, si č ottenuto il seguente schema relazionale:
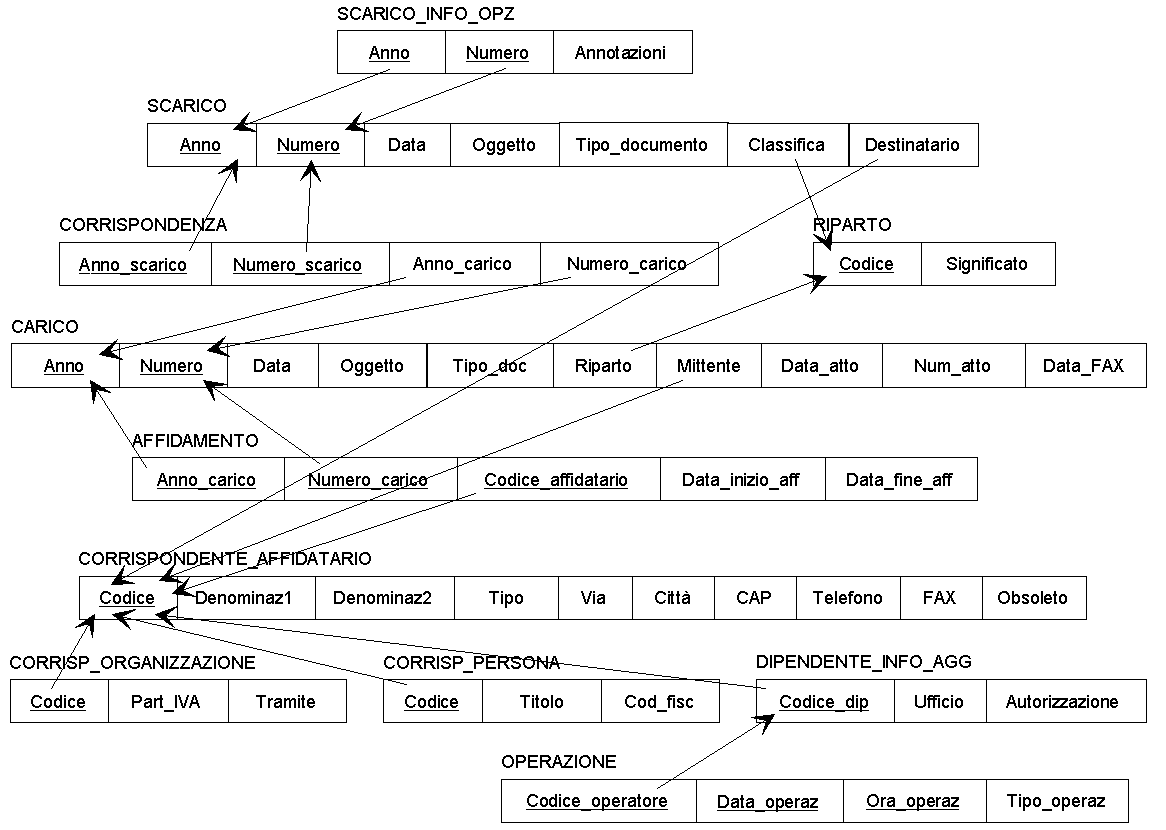
|
Per concludere, č importante osservare che tutte le decomposizioni introdotte sono senza perdita: gli attributi comuni alle relazioni prodotte da ciascuna decomposizione, infatti, sono chiave primaria per le relazioni stesse.
Qualitŕ dello schema relazionale secondo le "linee guida"
Linea guida 1: semantica/significato degli attributi. Gli schemi di relazione costruiti sono in generale chiari sia nel nome che negli attributi; a questi ultimi, in particolare, si č cercato di assegnare denominazioni chiare e univoche. L'unico schema di relazione potenzialmente poco chiaro č, come si puň capire, "CORRISPONDENTE_AFFIDATARIO", che memorizza informazioni su oggetti concettualmente diversi; come giŕ spiegato, comunque, questa poca chiarezza č stata accettata dal gruppo in cambio di una maggiore efficienza.
Linea guida 2: valori ridondanti e anomalie. Nello schema relazionale non ci sono valori ridondanti: infatti, ogni tupla di ogni relazione contiene informazioni relative ad uno e un solo oggetto (un documento, una persona, un'operazione sulla base dati, ecc.), e gli attributi di ogni relazione sono omogenei. Non ci sono anomalie di inserimento. Non ci sono anomalie di cancellazione, anche perché, grazie all'attributo "Obsoleto", le informazioni piů importanti non vengono mai veramente cancellate dalla base di dati. Esiste invece una anomalia di modifica relativa alla relazione "CORRISPONDENTE_AFFIDATARIO": modificando gli attributi "Denominaz1" o "Denominaz2" di una tupla, ad esempio per correggere un errore di inserimento, potrebbe accadere che due tuple acquistino gli stessi valori di "Denominaz1" e "Denominaz2", ovvero che diventino due rappresentazioni dello stesso oggetto (si ricordi lo schema concettuale); sfortunatamente, perň, la modifica verrebbe accettata senza problemi dal DBMS, dato che le due tuple continuerebbero ad avere un valore diverso per la chiave primaria "Codice". Questa anomalia dovrŕ sicuramente essere affrontata in sede di progettazione fisica, ad esempio introducendo nel software applicativo un controllo di consistenza dopo ogni modifica degli attributi "Denominaz1" e "Denominaz2".
Linea guida 3: valori nulli. Purtroppo, nella realtŕ che la base di dati deve rappresentare i valori nulli sono molto frequenti: ciň č emerso chiaramente sia durante la ristrutturazione dello schema E-R che nel passaggio allo schema relazionale. Nel progettare gli schemi di relazione, si č comunque cercato di fare il possibile per evitare di memorizzare valori nulli.
Linea guida 4: tuple "spurie". Nelle operazioni di JOIN tra relazioni non possono generarsi tuple spurie, perché gli schemi di relazione sono stati pensati per effettuare i JOIN usando sempre chiavi primarie o attributi che costituiscono chiavi esterne. Al contrario, usando l'operazione di inner join si puň avere una "perdita di tuple": ad esempio, eseguendo un inner join delle relazioni "SCARICO" e "SCARICO_INFO_OPZ" compariranno nel risultato solo quei pochi documenti che presentano anche l'attributo "Annotazioni". Questo potenziale problema potrŕ essere risolto durante la progettazione fisica a livello di software applicativo o, se il DBMS lo permetterŕ, ricorrendo alla funzione di outer join.
Normalizzazione dello schema relazionale
Prima forma normale. Alcuni attributi contengono valori concettualmente non atomici: l'attributo "Via" contiene sia il nome che il numero della via, e in alcuni casi l'attributo "Denominaz2" contiene sia la divisione che la sezione di un ministero; anche l'attributo "Annotazioni", non avendo una struttura ben definita, potrebbe contenere valori non atomici. Nella realtŕ per la quale la base di dati č stata progettata, queste situazioni non rappresentano perň violazioni della prima forma normale.
Seconda forma normale. In ciascuno schema di relazione, ogni attributo non primo dipende in modo funzionale completo dalla chiave primaria dello schema: lo schema relazionale, quindi, soddisfa la definizione di seconda forma normale.
Terza forma normale. Esistono alcune dipendenze funzionali tra attributi non appartenenti a chiavi primarie, ma tali dipendenze esulano dai confini della realtŕ che si vuole rappresentare e possono quindi essere trascurate: ad esempio, l'attributo "CAP" dipende funzionalmente dagli attributi "Via" e "Cittŕ" ma, dato che non si vuole mantenere una tabella dei CAP di tutta Italia, una simile dipendenza non viene considerata.
| NEXT: progettazione fisica | Indice della documentazione |
| PREV: progettazione concettuale | Home page del Corso |