|
|
103 |
|
|
|
|
computing the intermediate dissimilarity coefficient, will need to make a choice of cluster representative ab initio.
These cluster representatives are then 'improved' as the algorithm, adjusting the classification according to some objective function, steps through its iterations.
Cluster-based retrieval
Cluster-based retrieval has as its foundation the cluster hypothesis, which states that closely associated documents tend to be relevant to the same requests. Clustering picks out closely associated documents and groups them together into one cluster. In Chapter 3, I discussed many ways of doing this, here I shall ignore the actual mechanism of generating the classification and concentrate on how it may be searched with the aim of retrieving relevant documents.
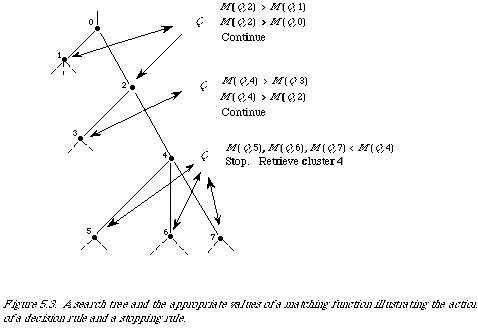
Suppose we have a hierarchic classification of documents then a simple search strategy goes as follows (refer to Figure 5.3 for details).
The search starts at the root of the tree, node 0 in the example.
It proceeds by evaluating a matching function at the nodes immediately descendant from node 0, in the example the nodes 1 and 2.
This pattern repeats itself down the tree.
The search is directed by a decision rule, which on the basis of comparing the values of a matching function at each stage decides which node to expand further.
Also, it is necessary to have a stopping rule which terminates the search and forces a retrieval.
In Figure 5.3 the decision rule is: expand the node
|
|
|
103 |
|
|
|