|
|
120 |
|
|
|
|
convenience let us set
There are a number of ways of looking at Ki. The most interesting interpretation of Ki is to say that it measures the extent to which the ith term can discriminate between the relevant and non-relevant documents.
Typically the 'weight' Ki(N,r,n,R) is estimated from a contingency table in which N is not the total number of documents in the system but instead is some subset specifically chosen to enable Ki to be estimated. Later I will use the above interpretation of Ki to motivate another function similar to Ki to measure the discrimination power of an index term.
The index terms are not independent
Although it may be mathematically convenient to assume that the index terms are independent it by no means follows that it is realistic to do so. The objection to independence is not new, in 1964 H. H. Williams[9] expressed it this way: 'The assumption of independence of words in a document is usually made as a matter of mathematical convenience. Without the assumption, many of the subsequent mathematical relations could not be expressed. With it, many of the conclusions should be accepted with extreme caution.' It is only because the mathematics become rather intractable if dependence is assumed that people are quick to assume independence. But, 'dependence is the norm rather than the contrary' to quote the famous probability theorist De Finetti[10]. Therefore the correct procedure is to assume dependence and allow the analysis to simplify to the independent case should the latter be true. When speaking of dependence here we mean stochastic dependence; it is not intended as logical dependence although this may imply stochastic dependence. For IR data, stochastic dependence is simply measured by a correlation function or in some other equivalent way. The assumption of dependence could be crucial when we are trying to estimate P(relevance/document) in terms of P(x/wi) since the accuracy with which this latter probability is estimated will no doubt affect the retrieval performance. So our immediate task is to make use of dependence (correlation)between index terms to improve our estimate ofP(x/wi) on which our decision rulerests.
|
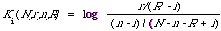
|
|
120 |
|
|
|