|
|
123 |
|
|
|
|
probability function P(x), and of course a better approximation than the one afforded by making assumption A1*.
The set on which the approximation is defined can be arbitrary, it might be the entire collection, the relevant documents (w1), or the non-relevant documents (w2).
For the moment I shall leave the set unspecified, all three are important.
However, when constructing a decision rule similar to D4 we shall have to approximate P(x/w1) and P(x/w2).
The goodness of the approximation is measured by a well known function (see, for example, Kullback[12]); if P(x) and Pa(x) are two discrete probability distributions then
* That this is indeed the case is shown by Ku and Kullback[11]. is a measure of the extent to which Pa(x) approximates P(x). In terms of this function we want to find a distribution of tree dependence Pt(x) such that I(P,Pt) is a minimum. Or to put it differently to find the dependence tree among all dependence trees which will make I(P,Pt) as small as possible.
If the extent to which two index terms i and j deviate from independence is measured by the expected mutual information measure (EMIM) (see Chapter 3, p 41).
then the best approximation Pt(x), in the sense of minimising I(P,Pt), is given by the maximum spanning tree (MST) (see Chapter 3, p.56) on the variables x1, x2, ..., xn . The spanning tree is derived from the graph whose nodes are the index terms 1,2, ..., n, and whose edges are weighted with I(xi,xj). The MST is simply the tree spanning the nodes for which the total weight
is a maximum. This is a highly condensed statement of how the dependence tree is arrived at, unfortunately a fuller statement would be rather technical. A detailed proof of the optimisation procedure can be found in Chow and Liu[13]. Here we are mainly interested in the application of the tree structure.
One way of looking at the MST is that it incorporates the most significant of the dependences between the variables subject to the global constraint that the sum of them should be a maximum. For |
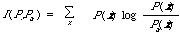
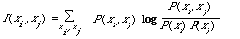
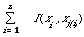
|
|
123 |
|
|
|