|
|
124 |
|
|
|
|
example, in Figure 6.1 the links between the variables (nodes,
x1, ..., x6) have been put in just because the sum
I(x1,x2) +I(x2,x3) + I(x2,x4) + I(x2,x5) + I(x5/x6)
is a maximum. Any other sum will be less than or equal to this sum. Note that it does not mean that any individual weight associated with an edge in the tree will be greater than one not in the tree, although this will mostly be the case.
Once the dependence tree has been found the approximating distribution can be written down immediately in the form A2. From this I can derive a discriminant function just as I did in the independent case.
ti= Prob(xi = 1/xj(i) = 1)
ri = Prob (xi = 1/xj(i) = 0) and r1 = Prob (x1 = 1)
P(xi /xj(i)) = [ti[xi](1 - ti)[1][- xi]] [xj(i) []ri[xi ](1 - ri)[1][- xi]][1][- xj(i)]
then
This is a non-linear weighting function which will simplify to the one derived from A1 when the variables are assumed to be independent, that is, when ti = ri. The constant has the same interpretation in terms of prior probabilities and loss function. The complete decision function is of course g(x) = log P(x/w1) - log P(x/w2)
which now involves the calculation (or estimation) of twice as many parameters as in the linear case. It is only the sum involving xj(i) which make this weighting function different from the linear one, and it is this part which enables a retrieval strategy to take into account the fact that xi depends on xj(i). When using the weighting function a document containing xj(i), or both xi and xj(i), will receive a contribution from that part of the weighting function.
It is easier to see how g(x) combines differentweights for different terms if one looks at the weights contributed tog(x) for a given |
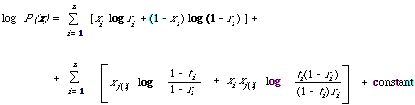
|
|
124 |
|
|
|