|
|
125 |
|
|
|
|
document x for different settings of a pair of variables xi ,xj(i).
When xi = 1 and xj(i) = 0 the weight contributed is
and similarly for the other three settings of xi and xj(i).
This shows how simple the non-linear weighting function really is. For example, given a document in which i occurs but j(i) does not, then the weight contributed to g(x) is based on the ratio of two probabilities. The first is the probability of occurrence of i in the set of relevant documents given that j(i) does not occur, the second is the analogous probability computed on the non-relevant documents. On the basis of this ratio we decide how much evidence there is for assigning x to the relevant or non-relevant documents. It is important to remember at this point that the evidence for making the assignment is usually based on an estimate of the pair of probabilities.
Estimation of parameters
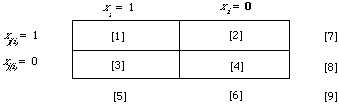
The use of a weighting function of the kind derived above in actual retrieval requires the estimation of pertinent parameters. I shall here deal with the estimation of ti and ri for the non-linear case, obviously the linear case will follow by analogy. To show what is involved let me given an example of the estimation process using simple maximum likelihood estimates. The basis for our estimates is the following 2-by-2 table.
Here I have adopted a labelling scheme for the cells in which [x] means the number of occurrences in the cell labelled x. Ignoring for the moment the nature of the set on which this table is based; our estimates might be as follows:
|
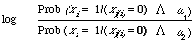
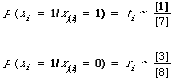
|
|
125 |
|
|
|