|
|
136 |
|
|
|
|
probability functions we can write the information radius as follows:
The interesting interpretation of the information radius that I referred to above is illustrated most easily in terms of continuous probability functions. Instead of using the densities p(./w1) and p(./w2) I shall use the corresponding probability measure u1 and u2. First we define the average of two directed divergencies[25], R (u1, u2/v) = uI (u1/v) +vI (u2/v)
where I(ui/v) measures the expectation on ui of the information in favour of rejecting v for ui given by making an observation; it may be regarded as the information gained from being told to reject v in favour of ui. Now the information radius is the minimum
thereby removing the arbitrary v. In fact it turns out that the minimum is achieved when
v = u u1 + v u2
that is, an average of the two distributions to be discriminated. If we now adopt u and v as the prior probabilities then v is in fact given by the density
p(x) = p(x/w1) P(w1) + p(x/w2) P(w2)
defined over the entire collection without regard to relevance. Now of this distribution we are reasonably sure, the distribution u1 and u2 we are only guessing at; therefore it is reasonable when measuring the difference between u1 and u2 that v should incorporate as much of the information that is available. The information radius does just this.
There is one technical problem associated with the use of the information radius, or any other 'discrimination measure' based on all four cells of the contingency table, which is rather difficult to resolve. As a measure of discrimination power it does not distinguish between |
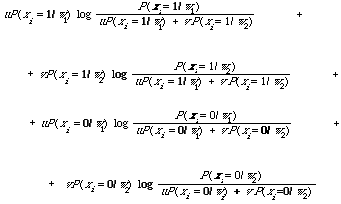
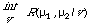
|
|
136 |
|
|
|